Linux系统下安装sysstat
sysstat是一个软件包,包含监测系统性能及效率的一组工具,这些工具对于我们收集系统性能数据,比如CPU使用率、硬盘和网络吞吐数据,这些数据的收集和分析,有利于我们判断系统是否正常运行,是提高系统运行效率、安全运行服务器的得力助手。
安装
$ yum install sysstat这个包一但安装下去,一般包括如下的几个命令可以使用。
sar、iostat、sa1、sa2、sadf、mpstat、sadc、sysstat
查看CPU使用情况:
$ sar -u 2 5 # 每隔2秒,显示5次,CPU使用的情况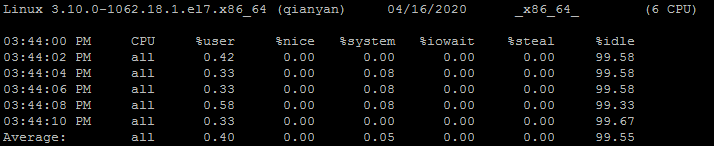
CPU:all 表示统计信息为所有 CPU 的平均值。
%user:显示在用户级别(application)运行使用CPU 总时间的百分比。
%nice:显示在用户级别,用于nice操作,所占用CPU 总时间的百分比。
%system:在核心级别(kernel)运行所使用CPU 总时间的百分比。
%iowait:显示用于等待I/O操作占用CPU 总时间的百分比。
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle:显示 CPU 空闲时间占用CPU 总时间的百分比。
Tips:
若 %iowait 的值过高,表示硬盘存在I/O瓶颈
若 %idle 的值高但系统响应慢时,有可能是CPU 等待分配内存,此时应加大内存容量
若 %idle 的值持续低于10,则系统的CPU 处理能力相对较低,表明系统中最需要解决的资源是CPU。
查看内存使用情况:
$ sar -r 2 5 # 每隔2秒,显示5次,内存使用的情况
查看网络吞吐量:
$ sar -n DEV 2 5 # 每隔2秒,显示5次,网络吞吐量情况
显示I/O和传送速率:
$ sar -b 1 5 # 每隔2秒,显示5次,I/O和传送速率的统计信息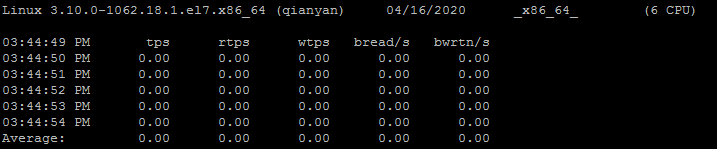
tps:每秒钟物理设备的 I/O 传输总量
rtps:每秒钟从物理设备读入的数据总量
wtps:每秒钟向物理设备写入的数据总量
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s
IO统计
$ iostat -x 1 10 # 每隔1秒统计一次,共显示10次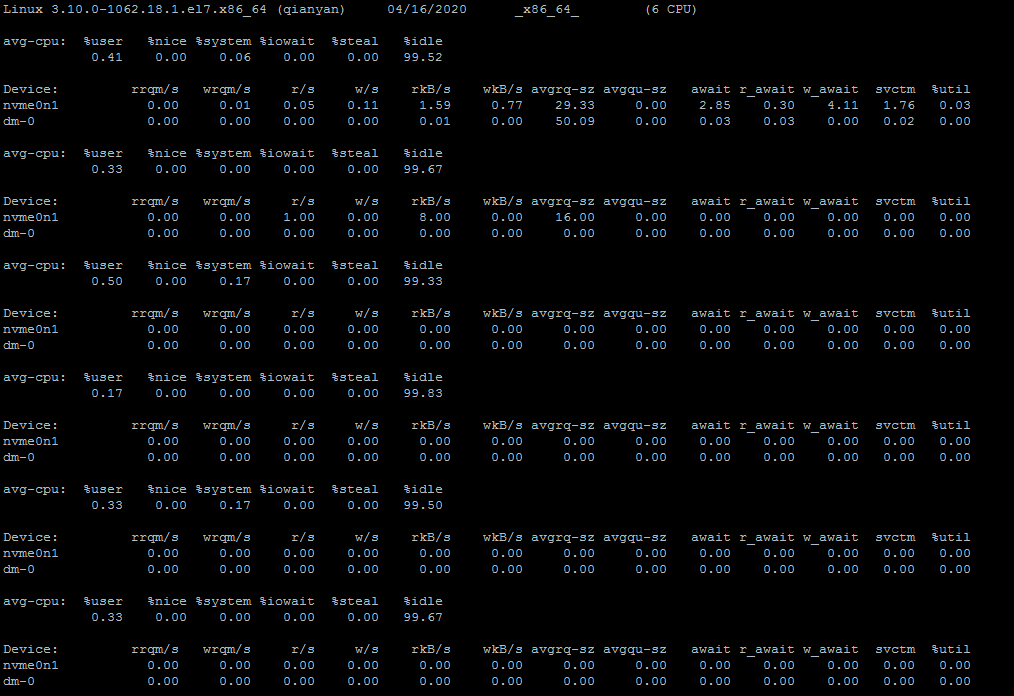
rrqm/s:每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s:每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s:每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s:每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s:每秒读扇区数。即 delta(rsect)/s
wsec/s:每秒写扇区数。即 delta(wsect)/s
rkB/s:每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s:每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz:平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await:平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm:平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util:一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000 (因为use的单位为毫秒)
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
idle小于70% IO压力就较大了,一般读取速度有较多的wait。 同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外还可以参考:
svctm 一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致 svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。
队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 问题。